Understanding Outliers: The Key To Data Analysis
Outliers are data points that deviate significantly from the rest of the dataset, and they play a crucial role in data analysis. Identifying and understanding outliers can lead to valuable insights in various fields, including finance, healthcare, and social sciences. This article will explore the concept of outliers, their implications, and how they can impact data-driven decisions.
As we delve into the world of statistics, it becomes clear that outliers are not merely anomalies; they can indicate errors, unusual events, or significant trends. Analyzing outliers is essential for accurate data interpretation and ensuring the integrity of statistical models. In this article, we will provide a comprehensive overview of outliers, their classification, methods for detection, and their influence on data analysis.
Through a structured approach, we will discuss various aspects of outliers, including their causes, the techniques used to identify them, and the strategies for handling them effectively. Whether you are a data scientist, researcher, or business analyst, understanding outliers will enhance your analytical skills and decision-making processes.
Table of Contents
- What Are Outliers?
- Types of Outliers
- Causes of Outliers
- Detecting Outliers
- The Impact of Outliers on Data Analysis
- Handling Outliers: Strategies and Techniques
- Case Studies: Outliers in Real Life
- Conclusion
What Are Outliers?
Outliers are observations that lie outside the general distribution of data. They can be defined statistically as data points that fall below the 1.5 interquartile range (IQR) from the first quartile or above the 1.5 IQR from the third quartile. However, this definition can vary based on the context of the data.
In a broader sense, outliers can be categorized as:
- Point Outliers: These are individual data points that are significantly different from the rest of the dataset.
- Contextual Outliers: These are data points that are considered outliers in a specific context but may not be unusual in a different context.
- Collective Outliers: These are groups of data points that exhibit abnormal behavior when considered together.
Types of Outliers
Understanding the different types of outliers is important for data analysis. Here are the main categories:
1. Univariate Outliers
Univariate outliers occur when a single variable deviates from the expected range. For instance, in a dataset of test scores, a score of 1000 could be considered a univariate outlier.
2. Multivariate Outliers
Multivariate outliers involve multiple variables. A data point may be considered an outlier when it deviates from the expected values of other variables in the dataset. For example, a person with an exceptionally high income but low education level might be a multivariate outlier.
Causes of Outliers
Outliers can arise from various sources, including:
- Measurement Errors: Mistakes in data collection or entry can lead to erroneous data points.
- Experimental Errors: Flaws in the experimental design can produce outlier results.
- Natural Variability: Some outliers are simply a result of natural variation within a population.
- Novel Events: Outliers can indicate significant, rare events that may require further investigation.
Detecting Outliers
Detecting outliers is a critical step in data analysis. Several methods can be employed to identify outliers, including:
1. Statistical Tests
Statistical tests such as the Z-score and the Grubbs' test can be used to detect outliers based on their distance from the mean.
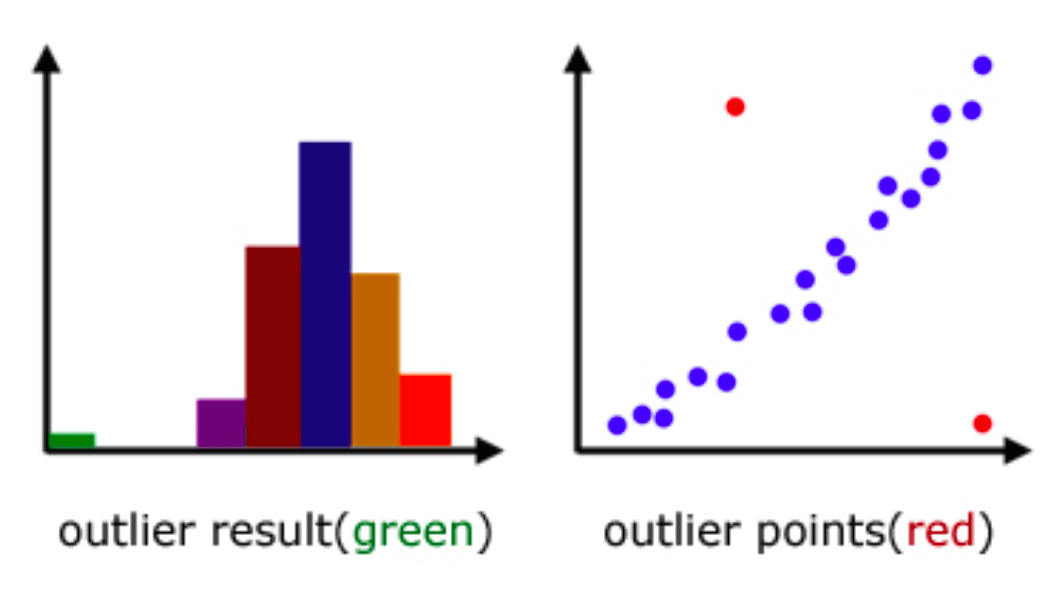
2. Visual Techniques
Visualization methods like box plots and scatter plots can help identify outliers by providing a visual representation of the data distribution.
The Impact of Outliers on Data Analysis
Outliers can significantly influence the results of statistical analyses, leading to skewed interpretations. Some potential impacts include:
- Affecting Mean and Standard Deviation: Outliers can distort the mean and standard deviation, making them unreliable measures of central tendency.
- Influencing Regression Analysis: Outliers can disproportionately affect regression coefficients, leading to incorrect conclusions.
- Masking Trends: The presence of outliers can obscure underlying trends in the data.
Handling Outliers: Strategies and Techniques
Once outliers are identified, it is essential to decide how to handle them effectively. Some strategies include:
1. Removing Outliers
In some cases, it may be appropriate to remove outliers from the dataset, especially if they are due to measurement errors.
2. Transforming Data
Applying transformations, such as logarithmic or square root transformations, can help mitigate the effects of outliers.
Case Studies: Outliers in Real Life
Outliers are present in various fields, and analyzing them can provide valuable insights. Here are a few case studies:
- Finance: In stock market analysis, extreme price fluctuations can be considered outliers that indicate market volatility.
- Healthcare: Patient data may reveal outliers that suggest rare medical conditions requiring further investigation.
- Social Sciences: Outliers in survey data may indicate unique demographic groups or behaviors that warrant further study.
Conclusion
Outliers are an integral part of data analysis that cannot be ignored. Understanding their significance, causes, and implications is essential for making informed decisions. By employing appropriate detection and handling strategies, analysts can enhance the accuracy and reliability of their findings.
If you found this article helpful, please leave a comment, share it with others, or explore more articles on our site to expand your knowledge on data analysis!
US Mobile: The Ultimate Guide To Affordable Wireless Plans
Understanding Lee: A Deep Dive Into The Life And Legacy
Exploring The Life And Work Of Vivi.xx3: A Comprehensive Guide





{kind=link}